Building a basic multiprocess worker in python
I’ve recently been working quite a bit on a worker application in python. This worker picks up tasks over a gRPC service executes those tasks, and publishes the results via gRPC. Because of python’s Global Interpreter Lock (GIL), threads don’t help for CPU intensive workloads. Instead, I’m using multiprocessing to run additional processes per worker and get better CPU utilization at the cost of using a ton of memory. When a python process opens a child process it can also share state with the child process. The most interesting of these are synchronization and communication primitives like Event, Queue, Pipe, and Lock. At a high level the worker’s workflow is:
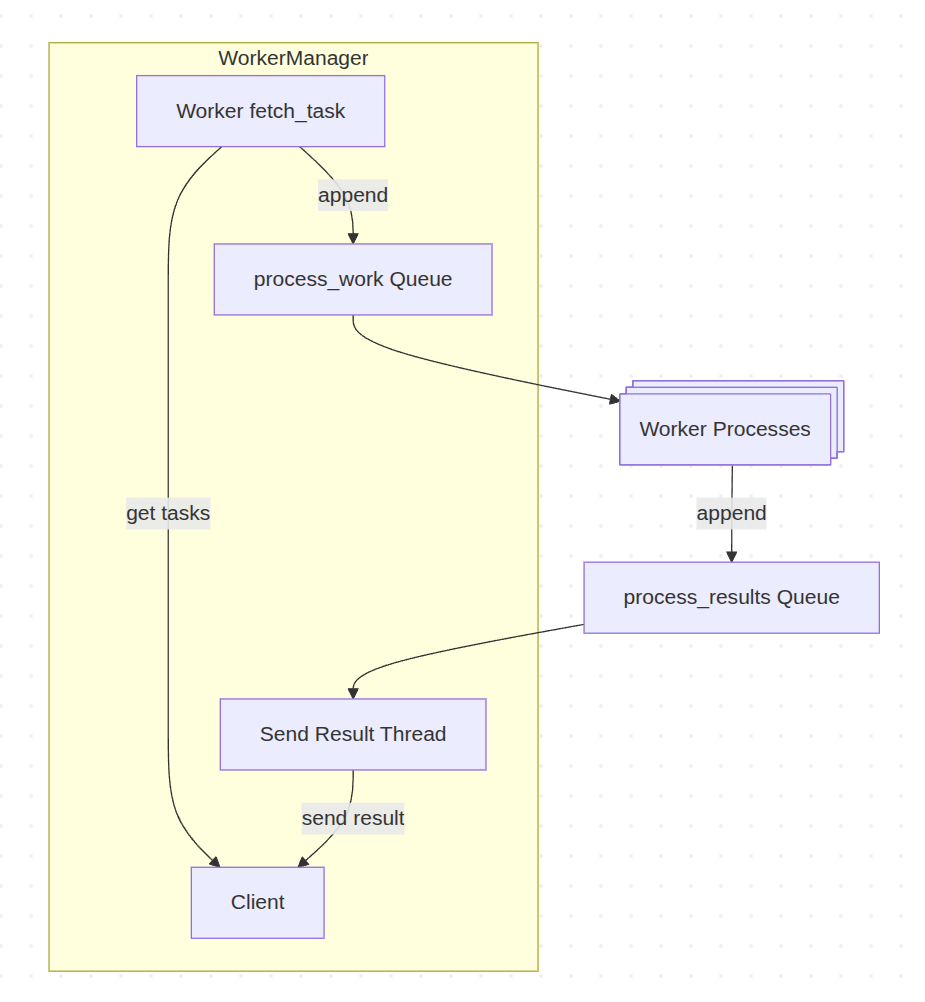
Theoretically, N is limited by how much memory and cores you have. In practice though, I’ve found I had diminishing results with N over 16. More than that, and I found my processes were wasting a lot of memory, and not getting much additional throughput as multiprocessing is using sockets under the hood to pass messages between processes, and there is serialization and locking overhead with those constructs.
Fetching work
While my worker fetches tasks via a gRPC API, the source of work can be a variety of things, HTTP requests, kafka message, MQ message etc. We’ll call this a TaskClient. Our worker uses the client to fetch one or more tasks from its underlying data stream. For this prototype, we’ll start with something very simple:
- class StubClient:
- def __init__(self, count: int = 100):
- self._remaining = count
- self._updates: dict[str, str] = {}
- def fetch_task(self):
- # This could be an RPC call that returns a more complex
- # object. I've used a simple dictionary as a prototype
- if self._remaining <= 0:
- return None
- self._remaining -= 1
- return {
- "task_id": uuid.uuid4().hex,
- "name": "echo",
- "payload": f"task # {self._remaining + 1}"
- }
- def update_task(self, task_id: str, status: str):
- # This could be an RPC call that returns a result object
- self._updates[task_id] = status
This is just a stub implementation, but this could easily have a gRPC, HTTP, or SQL backend. Next we have the bulk of our logic the WorkerManager. This class has a few responsibilities:
1. Using the client to fetch tasks and publish results.
2. Manage the pool of worker processes.
3. Handle shutdown.
Our WorkerManager needs a constructor and a way to start its processes up:
- class WorkerManager:
- def __init__(self, client: StubClient, process_count: int = NUM_PROCESS, queue_size: int = 10) -> None:
- self._client = client
- self._process_count = process_count
- # One queue to send work to the processes, and another to receive results.
- self._process_work: multiprocessing.Queue = multiprocessing.Queue(maxsize=queue_size)
- self._process_results: multiprocessing.Queue = multiprocessing.Queue(maxsize=queue_size)
- # We could use multiprocessing.ProcessPool, but I learned more doing it the hard way.
- self._processes: list[multiprocessing.Process] = []
- # We want to publish results on a thread, and keep our main thread for fetching tasks.
- self._result_thread: threading.Thread | None = None
- # We'll use this to shut down our result_thread later.
- self._shutdown = threading.Event()
- def start_processes(self) -> None:
- # Check existing workers for aliveness, and spawn more minions as required.
- processes = [p for p in self._processes if p.is_alive()]
- if len(processes) == self._process_count:
- return
- while len(processes) < self._process_count:
- # I'll cover run_task later
- p = multiprocessing.Process(target=run_task, args=(self._process_work, self._process_results))
- processes.append(p)
- p.start()
- self._processes = processes
I’m using a bunch multiprocessing objects here. The Queue instances let us communicate with our worker processes. These queues should always be bounded. Eventually appending to them will block which provides some natural backpressure and helps keep memory usage bounded. Once work has been fetched, it needs to be appended to then process_work queue, which each of our worker processes consumes from. We add the following to WorkerManager
- def _fetch_tasks(self) -> None:
- task = self._client.fetch_task()
- if not task:
- # Backoff and wait for task to arrive
- time.sleep(1)
- return
- # Could fail with queue.Full
- self._process_work.put(task)
We also need to start our result thread, have a run loop, and shutdown for our worker:
- def _start_send_result_thread(self) -> None:
- # This function will run in a thread. While threads in python
- # aren't great when you want concurrent CPU work, they are ok on IO
- # tasks like network.
- def send_result() -> None:
- while True:
- try:
- # Read results from worker processes.
- result = self._process_results.get(timeout=1.0)
- self._client.update_task(result["task_id"], result["status"])
- except queue.Empty:
- # We have drained the queue and we've been shutdown.
- if self._shutdown.is_set():
- return
- continue
- self._result_thread = threading.Thread(
- name="send-result", target=send_result, daemon=True
- )
- self._result_thread.start()
- def run(self):
- self.start_processes()
- self._start_send_result_thread()
- # When the process gets SIGINT/SIGTERM try to shutdown cleanly.
- atexit.register(lambda: self.shutdown())
- while True:
- self._fetch_tasks()
- # Simulate latency with sleep
- time.sleep(0.05)
- # To handle if a processes dies, while not possible in this prototype,
- # it could happen as workers could oom, or crash.
- self.start_processes()
- def shutdown(self) -> None:
- # Trigger shutdown to synchronize result thread
- self._shutdown.set()
- # Terminate and wait for all the child processes to die.
- for p in self._processes:
- p.terminate()
- p.join()
- # Wait for the result thread to shutdown.
- if self._result_thread:
- self._result_thread.join(timeout=5)
One thing I like about this approach is that we have separated our IO work (fetching tasks and sending results) from our CPU/IO workload (executing tasks). With fetching and result sending in separate threads, we do our best to execute keep the CPU busy. If fetch/update operations are expensive we have a lot of flexibility on batching as well. From my experience if you have long running tasks, fetching them individually is totally fine. In higher throughput scenarios, or where IO is expensive batching can work out better as you can fetch blocks of work, and publish batches of results.
Executing work
The next stage of our worker is executing tasks. Up until now, our run_task function has been a TODO. What we need
is a worker loop that can consume from our process_work queue, and publish results to process_results. Ideally, we look up tasks by name from a registry, and execute them. Task functions contain arbitrary application logic that our worker is executing as background ‘tasks’ or ‘jobs’. My simple implementation, without the task lookup or error handling looks like:
- def run_task(
- process_work: multiprocessing.Queue,
- process_results: multiprocessing.Queue,
- ) -> None:
- # This function needs to be importable from the module scope
- # because of how multiprocessing works.
- while True:
- # Read from the queue in the manager process.
- try:
- task = process_work.get_nowait()
- except queue.Empty:
- continue
- # TODO look up tasks from a map of registered tasks
- # and call the user defined function. Catch errors
- # and provide retry behavior or mark tasks failed.
- do_work(task)
- result = {
- "task_id": task["task_id"],
- "status": "complete"
- }
- # Publish results back to the main process
- process_results.put(result)
- # Our 'task' to be executed. Ideally we use the task name
- # to locate the appropriate task and parse parameters.
- def do_work(task):
- print(f"Ran task {task}")
While, I’ve only implemented the most basic solution. In a more robust implementation, I would handle more task outcomes. Ideally tasks complete without errors and are complete. If the task function does raise an error, it is a failure. Within failure, there are failures that we can retry again later and see if we get a successful result. We can detect those scenarios from the task definition and return a retry status.
You can run the worker demo with:
- def main():
- client = StubClient()
- manager = WorkerManager(client)
- manager.run()
- if __name__ == "__main__":
- main()
After implementing a task registry system, I would also recommend adding task timeouts using with SIGALRM. A system like this also benefits from metrics and logging/tracing so that you can understand how your workloads are operating.
There are no comments, be the first!